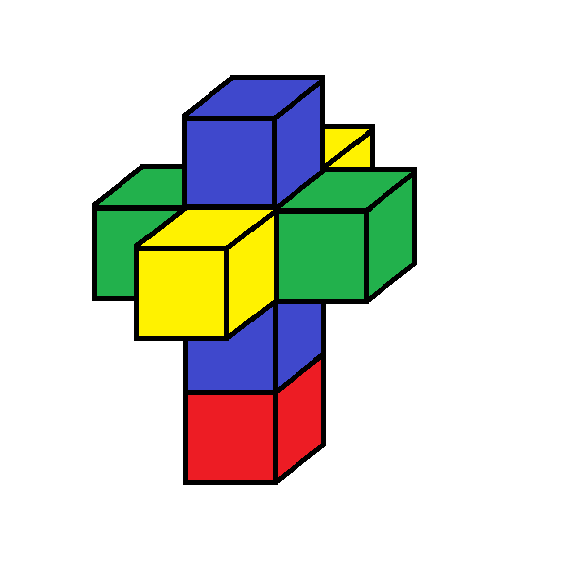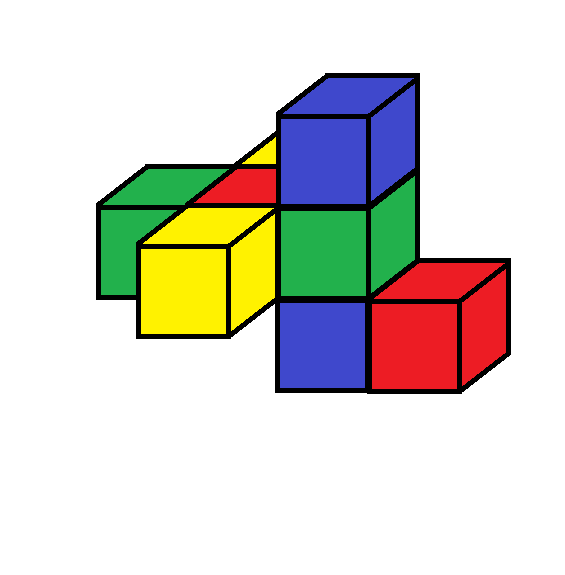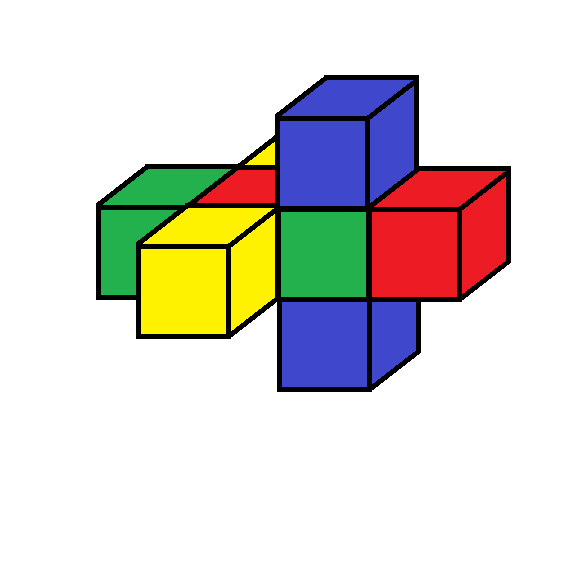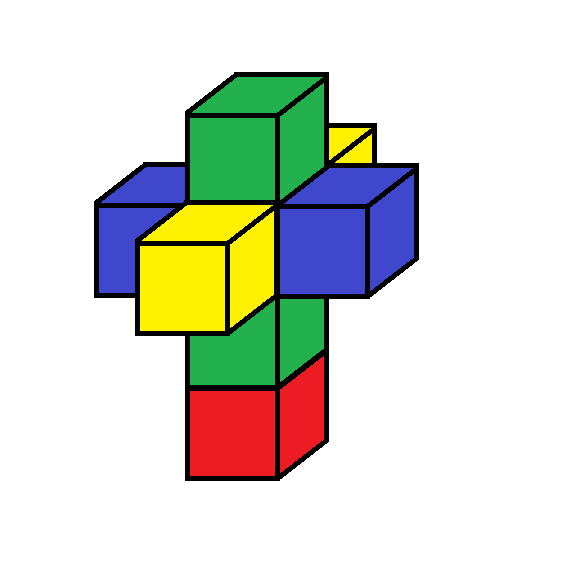Maybe somebody’s already done this, but not as far as I know!
The Wikipedia Tesseract article has a link to a 1984 article in the Journal of Recreational Mathematics, Unfolding the Tesseract . I had come upon this by following a circuitous path starting from a new NYT Sunday Magazine puzzle which involved tiling a small grid into “islands in an ocean” according to certain rules. This led me into unfoldings of the cube because a few years ago I had “discovered” a simple unfolding which very easily “tiled the plane” with simple translations.
So I looked into unfoldings of the cube and came upon the generalization of the idea in the form of the above cited article, which enumerates with hand illustrations the 261 unique unfoldings of the tesseract, based on topological reasoning.
I found the article to be fascinating, but I had to think about it a while to see how this seemingly abstract reasoning connected to the actual block models of these unfoldings, but I think I mastered it, at least in intuitive terms: ( click to enlarge! )
Note the “reduced” tree diagram I drew at the top, showing that a pair of “opposites” which occupy two root nodes indicate that they can be appended to opposite sides of a “flat” piece of six cubes, corresponding to an unfolding of a cube into a flat plane of squares. In this and several other cases on the page, it can be done in two different ways. In fact, such cases account for a significant fraction of all the unfoldings, and there are many such intricate relationships among these 261 models, as one might imagine.
These include the idea I developed of “pivoting” around an edge to produce two different unfoldings from a given unfolding. This happens wherever three of the cubes form an “elbow”. The opposing faces of the elbow represent a single 2-d face in the tesseract, and either of the indicated opposing cubes can be “rolled” or “pivoted” to abandon an existing attachment and form a new attachment ( which exists implicitly in the tesseract. )
In fact every edge of the tesseract is part of three faces, and a condition of the unfolding is that at most two of these faces can be attached. This leads to a very “thick” relationship among the various unfoldings. Considered in the original tesseract, the attachments represent 7 faces out of the 24, no 3 of which share a single edge. So the “pivot” operation represents a replacement of either of the two faces sharing an edge with the third face.
It occurred to me that I could generate all the unfoldings by repeatedly applying this pivot operation wherever possible.
To do so we must ascend, or descend, to the lexical realm, where mere strings of characters represent the multidimensional geometry of the n-cube.
This brings us to “grep notation”, in particular the notion that “.” represents a “wild card” match to any character. Here, our alphabet consists only of “0” and “1”, and a “.” which can match either of them. So for example, if we have a cube represented by 000 001 010 011 100 101 110 111, we can define the faces of the cube by 0.. 1.. .0. .1. 0.. 1.. , and in fact a UNIX grep with each of these strings will select the points of the square face from a file containing each of the eight points, so defined.
Well, this notion easily conquers all interdimensional boundaries, and in a very intuitive way. Note that the “faces” of any hypercube are represented by e.g. ….0…. …1….. etc. with a constant string length, and the shared “subface” of these two faces is …10…. Also note, and this is remarkable, that you can grep a list of the subfaces by a face representation and find the subfaces shared by it.
Thinking of all this, I wrote a program to generate all the unfoldings of the tesseract by iteratively applying the pivot operations to the sets of new unfoldings found by the previous iteration. This requires that each unfolding be represented by a canonically unique element among the 2^n * n! representations related by reflections along each axis and permutations of the axis labels. ‘nuf said.
The familiar “cross” unfolding of the cube generalizes in a natural way to any dimension, and in four dimensions ( unfolded to three ) it is featured in the R. A. Heinlein story, And He Built a Crooked House.
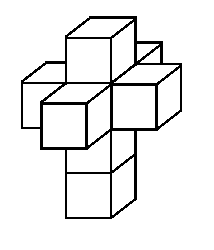
In canonical grep notation this is:
..00 ..01 ..10 .0.0 .1.0 0..0 1..0
This is the “lexically least” of the 384 transformations comprised of the possible “flips”
( 0 1 ) of any set of axes along with “swaps” between pairs of axes generating all permutations of the ordering, applied to each of the face representations. The seven face reps are sorted on each line, and the lexically least of these is chosen as the canonical representation of the unfolding.
Since a line with ..00 will always “come out on top” we need only generate representations which contain it. This is done by applying a transformation which maps each term, in turn, to ..00, then applying the 16 transformations that leave ..00 invariant. This reduces the number of canonical candidates to 112. All this is done internally by the “canon” command:
$ echo “.0.0 ..10 ..00 ..01 1..0 .1.0 0..0” | canon
..00 ..01 ..10 .0.0 .1.0 0..0 1..0
( In this case all it had to do is sort the terms on the line. )
Starting from this canonical representation, note that there are 24 possible “pivots” :
$ pivot < net1 | wc -l
24
but only 5 canonically distinct results:
$ pivot < net1 | canon | sort -u | wc -l
5
Proceeding in this way, and eliminating duplicates at each stage, I found that I got all 261 unfoldings of the tesseract with five iterations applied to the original representation:
$ wc -l net*
1 net1
5 net2
38 net3
118 net4
91 net5
8 net6
261 total
So, moving right along, starting from:
…00 …01 …10 ..0.0 ..1.0 .0..0 .1..0 0…0 1…0
and using the same programs, mutatis mutandis, I found the unfoldings into 4-space of the 5-cube, mentioned in the cited 1984 article as being possibly intractable:
$ wc -l net*
1 net1
5 net2
47 net3
344 net4
1902 net5
4836 net6
2489 net7
70 net8
9694 total
So there’s the answer! I don’t see anything relevant with a search on 9694, so I’m sticking with the fond hope that this is an actual original result.
I’ll mention that I did this manually in stages using the sort and uniq UNIX command ( but not grep ! ) along with my purpose written C programs “pivot” and “canon”. The command with the longest elapsed time was:
$ time pivot < net6 | canon | sort -u >net7
real 1m47.384s
user 1m49.090s
sys 0m0.045s
The Power of the Pivot
It’s puzzling that this geometric idea of the Pivot should give the same enumeration as the one based on topological “pairings” . I can’t spell it all out yet, but here is an indication of why this works out. These pivot operations have simple intuitive rules and can be directly applied to the unfolded models, e.g. the 3d unfolding of the tesseract.
Here is an animated gif showing how a series of pivots can switch around the opposite pairs of cubes, which are namely ( 0…, 1…) ( .0.., .1..) (..0., ..1.) ( …0, …1) in the grep notation. In the animation each pair is indicated by a separate color. The animation shows how the green and blue pairs can be switched by a sequence of pivots, even though they are not symmetrically placed. In the first place the green and yellow pairs are symmetrically equivalent, but after the switch the blue and yellow pairs have that symmetrical placement.
In general, it must be true that the pivot operations produce all the equivalent configurations with the 24 permutations among the colors.
Here, the last frame of the animation shows a simple rotation of the resulting configuration for comparison with the initial configuration. Also the leftward motion of the blue cubes represents two pivots taking place at once.